
Calibrated Attention Masking Network for Temporal Action Localization
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
비디오 분석(Video Understanding) 분야에서 시간적 행동 구간 검출(Temporal Action Localization, TAL)은 단순히 동영상의 카테고리를 분류하는 것을 넘어, 특정 행동이 동영상의 몇 초에 시작해서 몇 초에 끝났는지(Start & End boundaries)를 검출해 내는 핵심 기술입니다.
하지만 행동 경계선 근처(Action boundaries)의 프레임들은 행동이 완전히 시작하기 직전의 모호한 상태를 담고 있어, 어텐션 가중치 분포가 흐려지고 정확한 타임스탬프를 검출하기 까다롭습니다.
본 포스트에서는 2026년 심사 중인 공동 연구 논문인 Calibrated Attention Masking Network의 경계 정밀화 메커니즘을 분석합니다.
1. 기존 TAL 모델의 한계점: 경계선 모호성
기존의 Self-Attention 기반 비디오 분석 트랜스포머는 비디오 전체 프레임 간의 전역 정보(Global Context)를 교환하는 데에는 능하지만, 시간적 경계 영역(Boundary frames)에서의 급격한 피처 전이(Feature Transition)를 포착하는 해상도가 떨어집니다.
- 행동 발생 시간 직전/직후의 프레임들에 불필요한 어텐션(Attention leakage)이 분산되어, 검출된 경계선이 실제 골프 스윙이나 댄스 시작 시각 대비 미세하게 밀리는 오차를 유발합니다.
2. Calibrated Attention Masking Network 핵심 메커니즘
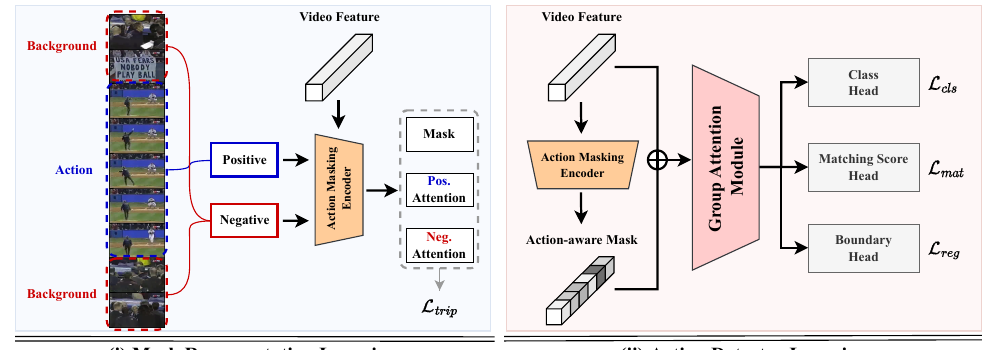
본 논문은 이러한 경계 불확실성을 보정하기 위해 캘리브레이션(Calibration) 필터와 동적 마스킹(Dynamic Masking) 구조를 융합했습니다.
① Attention Calibration Layer (어텐션 보정 레이어)
- 행동이 발생하지 않는 것으로 추정되는 배경(Background) 구간의 노이즈 피처를 강제로 억제(Suppress)합니다.
- 어텐션 신호의 Contrast(대비)를 수치적으로 증폭하여, 행동 시작 구간에서의 어텐션 가중치가 가파른 기울기(Step function에 가까운 형태)로 생성되도록 유도합니다.
② Dynamic Masking Module
- 경계선 신뢰도 점수(Boundary Confidence Score)가 모호한 프레임들에 대해 마스킹을 동적으로 적용하여, 모델이 강제로 양방향 잔여 프레임들의 정보 흐름(Bi-directional temporal flow)을 바탕으로 경계 시각을 완벽히 매핑해내도록 학습시킵니다.
3. 의의 및 결론
이 연구는 실시간 추론 연산 오버헤드를 높이지 않으면서도, 시간적 행동 구간 검출(TAL) 벤치마크 데이터셋에서 IoU 임계값 기준 검출 오차(t-IoU)를 비약적으로 개선했습니다. 스포츠 분석, CCTV 위험 행동 실시간 탐지 등 정확한 타임스탬프 검출이 필요한 다양한 실무 비디오 엔진의 완성도를 획기적으로 개선할 수 있는 기술적 돌파구를 제공합니다.
Calibrated Attention Masking Network for Temporal Action Localization
In video understanding, Temporal Action Localization (TAL) is the task of predicting not only the category of an action but also its precise start and end times within a video sequence.
However, frames near action boundaries are often ambiguous, leading to diffused attention weights and degraded localization precision.
This post analyzes the boundary refinement mechanism of the Calibrated Attention Masking Network, currently under review in 2026.
1. Challenges in TAL: Boundary Ambiguity
Conventional self-attention layers in video transformers are effective at capturing global context, but struggle with representing sharp transitions at action boundaries:
- Attention weights often leak into background frames adjacent to the action interval, causing predicted boundaries to shift slightly from the true onset of actions (e.g., the exact start of a golf swing).
2. Core Mechanism of Calibrated Attention Masking Network
To resolve boundary uncertainty, this architecture integrates an Attention Calibration Layer with a Dynamic Masking Module.
① Attention Calibration Layer
- Suppresses background feature noise in intervals where no target actions are predicted.
- Amplifies the contrast of attention weights, forcing a sharp increase in attention gradients at action boundaries.
② Dynamic Masking Module
- Dynamically masks frames with ambiguous boundary confidence scores during training. This forces the model to extrapolate boundaries based on bi-directional temporal contexts.
3. Impact & Conclusion
This network achieves state-of-the-art results on standard TAL benchmarks without increasing inference-time computational complexity. It provides an efficient solution for industrial video analytics where precise time localization is critical, such as sports event detection and real-time security monitoring.