
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
비디오 기반의 2D 인체 포즈 추정(Human Pose Estimation) 분야에서 가장 큰 비용이 발생하는 요인은 프레임 단위의 레이블링(Annotation)입니다. 이를 해결하기 위해 일부 프레임만 어노테이션되어 있는 드문 레이블 비디오(Sparsely-Labeled Videos)에서 포즈를 학습하는 연구가 주목받고 있습니다.
하지만 레이블이 부족한 상황에서는 사람이 다른 물체 뒤로 지나가는 가림 현상(Occlusion)이 발생할 경우, 모델이 관절의 위치를 전혀 예측하지 못하거나 심하게 흔들리는 문제가 생깁니다.
본 포스트에서는 IEEE SMC 2022 학회에서 구두 발표(Oral Presentation)를 진행했던 OTPose (Occlusion-Aware Transformer)의 핵심 메커니즘과 가림 극복 설계 방식에 대해 분석합니다.
1. 드문 레이블(Sparsely-Labeled) 비디오 포즈 추정의 난제
연속된 비디오 프레임 중 $N$ 프레임 간격(예: 5프레임 또는 10프레임 단위)으로만 정답 레이블이 존재하고, 사이 프레임은 비어있는 경우 다음과 같은 문제가 발생합니다:
- 정량 정보 부재: 레이블이 없는 프레임의 관절 정보는 직접적인 Supervised Loss를 줄 수 없습니다.
- 가림(Occlusion) 대응력 상실: 레이블이 촘촘할 때는 프레임 간 조인트 트래킹을 통해 위치를 유추할 수 있지만, 레이블이 드문 상태에서 특정 조인트가 사물에 가려지면 추정 오차가 무한히 커집니다.
2. OTPose 핵심 아키텍처
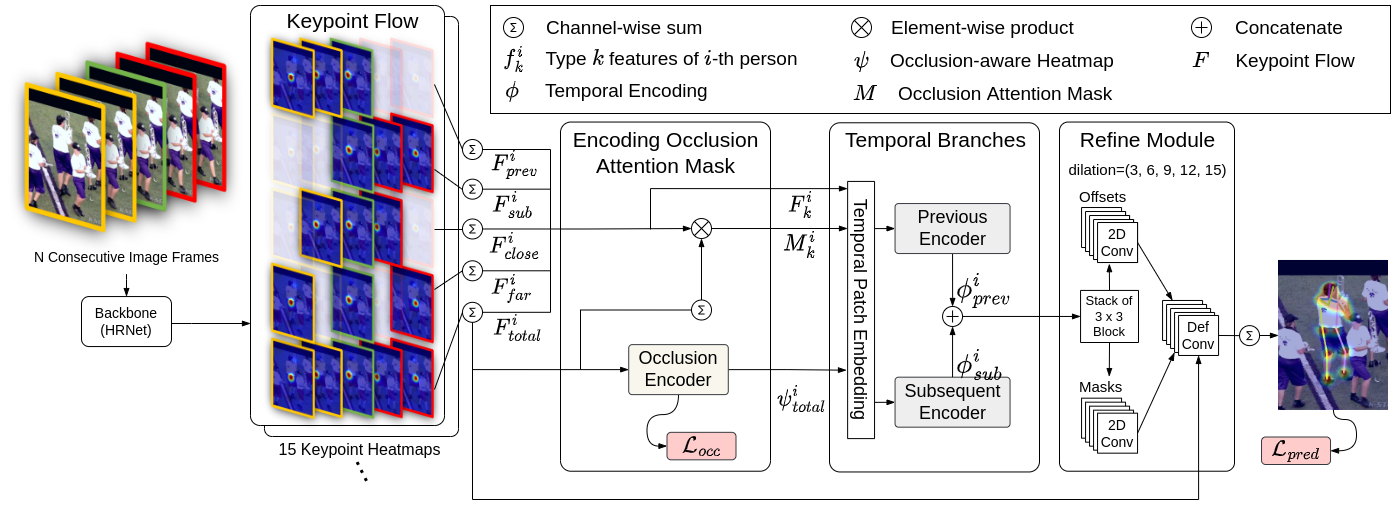
OTPose는 이미지 기반의 2D Detector(HRNet 등)를 통해 추출된 프레임별 키포인트 피처를 입력으로 받으며, 크게 Spatial-Temporal Transformer Encoder와 Occlusion Masking Module의 결합으로 구성됩니다.
1
2
3
4
5
6
7
8
9
10
[비디오 입력] ──> [2D Pose Detector (HRNet)] ──> [키포인트 Feature 추출]
│
▼
[Occlusion Masking Generator]
│
▼ (가상 마스킹 주입)
[Spatial-Temporal Transformer]
│
▼ (시공간 토큰 복원)
[Refined 2D Pose Output]
① Spatial-Temporal Tokenization
- Spatial Token: 한 프레임 내에서 머리, 골반, 발목 등 서로 다른 관절(Joint) 간의 신체 물리적 구조 관계를 학습합니다.
- Temporal Token: 동일한 관절이 프레임 흐름($t \to t+1$)에 따라 이동하는 운동 궤적(Trajectory) 정보를 학습합니다.
- 두 토큰을 통합하여 트랜스포머의 어텐션 맵(Attention Map)이 “지금 가려진 왼발의 위치는 3프레임 전의 왼발 궤적과 신체 중심선의 관계를 보아 이곳에 있을 것”을 추론하게 만듭니다.
② Self-Supervised Occlusion Masking Strategy
모델의 가림 극복 능력을 강제로 극대화하기 위해, 자가지도학습(Self-Supervised Learning) 방식의 가상 마스킹 기법을 도입했습니다.
- 학습 과정 중, 정답 레이블이 명확히 존재하는 프레임에서 일부 관절(예: 오른손)의 피처 값을 임의로 0으로 채우는 가상 마스킹(Artificial Masking)을 주입합니다.
- 모델은 마스킹된 관절에 대해 원래 정답 레이블이 존재했던 위치로 원복(Reconstruction)하도록 강제하는 Reconstruction Loss를 부여받습니다.
- 이 과정을 통해 모델은 추론(Inference) 단계에서 실제로 물체에 의해 가려진 관절이 들어왔을 때, 이를 가상 마스킹 상태로 인지하고 시공간 어텐션 정보를 활용해 가장 자연스러운 위치로 자동으로 복원해내게 됩니다.
3. 실험 및 성능 분석
OTPose는 대표적인 비디오 포즈 추정 벤치마크 데이터셋인 Sub-JHMDB 및 Penn Action에서 검증을 수행했습니다.
- 가림 복원 능력 검증: 인위적으로 관절을 마스킹하고 추정하는 테스트에서 기존 CNN 기반의 시간 연속성 모델(Seq-to-Seq 모델 등) 대비 3~4% 높은 관절 추정 정확도(PCKh@0.5)를 확보했습니다.
- 학습 효율성: 전체 비디오 프레임 중 단 10%의 레이블만 사용하는 환경에서도, 100% 레이블을 다 사용한 모델 성능의 약 95% 수준까지 도달하는 효율성을 입증했습니다.
4. 결론 및 의의
OTPose는 단순 후처리 필터링(Kalman Filter 등)을 사용해 떨림을 억제하던 기존 방식에서 탈피하여, 트랜스포머가 공간적 뼈대 정보와 시간적 모션 궤적을 융합적으로 이해하여 누락된 관절을 구조적으로 복원해내는 아키텍처를 제안했습니다. 이 개념은 향후 속도와 가속도 물리 법칙을 어텐션 메커니즘에 직접 주입한 HANet (WACV 2023) 연구의 든든한 초석이 되었습니다.
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos
In video-based 2D Human Pose Estimation (HPE), the most labor-intensive bottleneck is frame-by-frame annotation. To alleviate this, studying models that can learn pose representations from Sparsely-Labeled Videos (where only a few selected frames are annotated) has become a prominent research direction.
However, under data sparsity, when an target person passes behind obstacles—causing joint occlusion—models frequently lose track of keypoints or experience severe prediction jitter.
In this post, we analyze the core mechanisms and occlusion-handling design of OTPose (Occlusion-Aware Transformer), which was presented as an Oral Presentation at IEEE SMC 2022.
1. Challenges in Sparsely-Labeled Video Pose Estimation
When ground-truth labels exist only at dynamic intervals of $N$ frames (e.g., every 5 or 10 frames), models face two primary issues:
- Lack of Supervision: Empty intermediate frames cannot provide direct supervised gradients.
- Occlusion Vulnerability: While dense frame tracking helps estimate occluded keypoints, data sparsity causes keypoint regression errors to propagate when a joint is hidden behind obstacles.
2. Core Architecture of OTPose
OTPose receives keypoint features extracted from a frame-by-frame 2D detector (such as HRNet) and resolves missing features via a joint Spatial-Temporal Transformer Encoder and an Occlusion Masking Module.
1
2
3
4
5
6
7
8
9
10
[Video Input] ──> [2D Pose Detector (HRNet)] ──> [Keypoint Features]
│
▼
[Occlusion Masking Generator]
│
▼ (Inject Artificial Masks)
[Spatial-Temporal Transformer]
│
▼ (Reconstruct Masked Tokens)
[Refined 2D Pose Output]
① Spatial-Temporal Tokenization
- Spatial Tokens: Learn structural correlations between different human joints (e.g., head, pelvis, ankle) within a single frame.
- Temporal Tokens: Learn the motion trajectory of the same joint across consecutive frames ($t \to t+1$).
- By combining these tokens, the Transformer’s Attention Map learns to reason: “The current occluded left foot must be placed here based on its trajectory 3 frames ago and its relationship to the torso.”
② Self-Supervised Occlusion Masking Strategy
To maximize the model’s robustness to occlusions, we introduced a Self-Supervised Learning technique based on artificial masking:
- During training, on frames where ground-truth labels are fully available, we randomly set select joint features (e.g., right hand) to zero (Artificial Masking).
- The model is then trained with a Reconstruction Loss that forces it to reconstruct the original joint position of the masked feature.
- This training scheme enables the model to perceive real occlusions during inference as “artificial masks” and automatically reconstruct them using surrounding spatiotemporal contexts.
3. Experimental Results
OTPose was validated on standard video pose estimation benchmark datasets, including Sub-JHMDB and Penn Action.
- Robustness to Occlusion: Under artificial joint masking tests, OTPose achieved 3-4% higher joint estimation accuracy (PCKh@0.5) compared to conventional CNN-based seq-to-seq models.
- Label Efficiency: When trained on only 10% of the video frames labeled, OTPose recovered up to 95% of the accuracy achieved by the fully-supervised counterpart.
4. Conclusion & Impact
Rather than relying on post-processing heuristics (e.g., Kalman filtering) to smooth out coordinate jitters, OTPose proposed a structural solution: allowing a Transformer to implicitly model temporal motion trajectories and spatial skeletal configurations simultaneously. This concept laid the foundation for HANet (WACV 2023), which integrated physical constraints (velocity and acceleration) directly into its attention mechanism.