Tag CV
About Me 자기소개
자기소개 고려대학교 PRML 연구실 졸업 후 LG전자 선행 로봇 연구팀에서 멀티모달 지능 및 Embodied AI를 연구하고 있는 진경민입니다.

Tag WACV
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL [WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출 비디오 내 행동 구간 검출의 정확도를 높이기 위해 특정 행동 정보에 초점을 맞추는 그룹 기반 어텐션 및 액션 인지 마스킹 기법을 제안한 WACV 2023 Oral 논문 요약입니다.
![[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL](/assets/images/publications/action_aware_wacv2023_fig2.png)
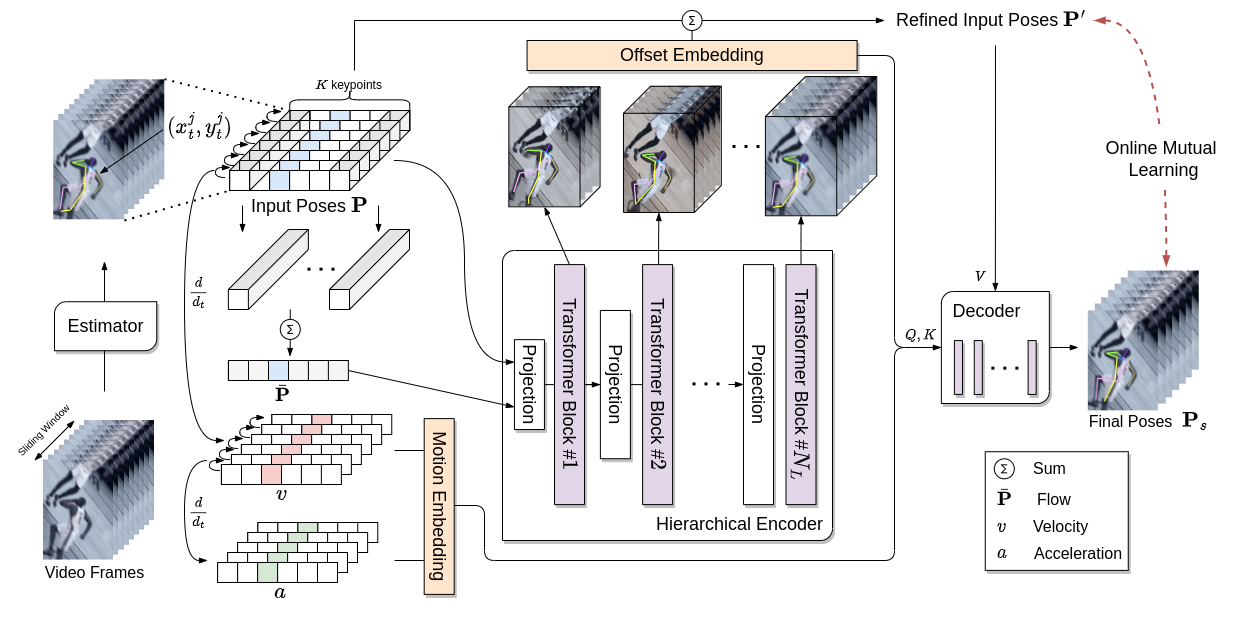
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation 비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet) 인체 관절의 물리적 운동 법칙(속도/가속도)을 활용해 비디오 포즈 떨림을 제어하는 계층적 어텐션 네트워크인 HANet(WACV 2023 Oral)과 M-HANet(Neural Networks 2024 저널) 연구의 핵심을 요약합니다.
Tag Journal-Neural-Networks
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation 비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet) 인체 관절의 물리적 운동 법칙(속도/가속도)을 활용해 비디오 포즈 떨림을 제어하는 계층적 어텐션 네트워크인 HANet(WACV 2023 Oral)과 M-HANet(Neural Networks 2024 저널) 연구의 핵심을 요약합니다.
Tag Pose-Estimation
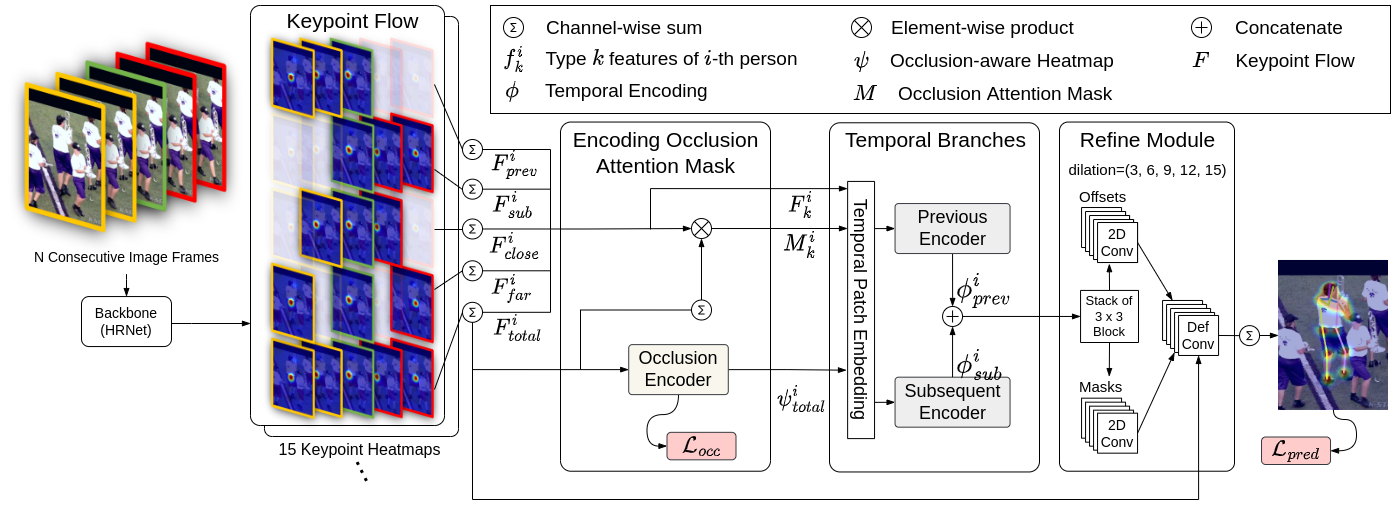
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer 프레임 일부만 레이블링된 비디오 환경에서 트랜스포머의 시간-공간 토큰 학습 및 셀프 지도 마스킹 기법을 통해 관절 가림 현상(Occlusion)을 복원하는 OTPose 프레임워크를 분석합니다.
Infant Behavior Video Analysis using Pose Estimation and Action Recognition Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안
Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안 영유아의 대근육 운동 발달 수준을 평가하고 예측하기 위해 DCPose 및 I3D 모델을 활용한 비디오 행동 분석 솔루션을 제안합니다.

Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation 비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet) 인체 관절의 물리적 운동 법칙(속도/가속도)을 활용해 비디오 포즈 떨림을 제어하는 계층적 어텐션 네트워크인 HANet(WACV 2023 Oral)과 M-HANet(Neural Networks 2024 저널) 연구의 핵심을 요약합니다.
Tag Attention
Calibrated Attention Masking Network for Temporal Action Localization 시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크 비디오 영상에서 특정 행동이 일어난 시작점과 끝점(시간적 경계)을 정밀하게 검출하기 위한 보정형 어텐션 마스킹(Calibrated Attention Masking) 기술에 대해 다룹니다.
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL [WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출 비디오 내 행동 구간 검출의 정확도를 높이기 위해 특정 행동 정보에 초점을 맞추는 그룹 기반 어텐션 및 액션 인지 마스킹 기법을 제안한 WACV 2023 Oral 논문 요약입니다.
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation 비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet) 인체 관절의 물리적 운동 법칙(속도/가속도)을 활용해 비디오 포즈 떨림을 제어하는 계층적 어텐션 네트워크인 HANet(WACV 2023 Oral)과 M-HANet(Neural Networks 2024 저널) 연구의 핵심을 요약합니다.
Tag Deep-Learning
Infant Behavior Video Analysis using Pose Estimation and Action Recognition Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안
Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안 영유아의 대근육 운동 발달 수준을 평가하고 예측하기 위해 DCPose 및 I3D 모델을 활용한 비디오 행동 분석 솔루션을 제안합니다.
Calibrated Attention Masking Network for Temporal Action Localization 시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크 비디오 영상에서 특정 행동이 일어난 시작점과 끝점(시간적 경계)을 정밀하게 검출하기 위한 보정형 어텐션 마스킹(Calibrated Attention Masking) 기술에 대해 다룹니다.
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation 비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet) 인체 관절의 물리적 운동 법칙(속도/가속도)을 활용해 비디오 포즈 떨림을 제어하는 계층적 어텐션 네트워크인 HANet(WACV 2023 Oral)과 M-HANet(Neural Networks 2024 저널) 연구의 핵심을 요약합니다.
Tag Action-Localization
Calibrated Attention Masking Network for Temporal Action Localization 시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크 비디오 영상에서 특정 행동이 일어난 시작점과 끝점(시간적 경계)을 정밀하게 검출하기 위한 보정형 어텐션 마스킹(Calibrated Attention Masking) 기술에 대해 다룹니다.
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL [WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출 비디오 내 행동 구간 검출의 정확도를 높이기 위해 특정 행동 정보에 초점을 맞추는 그룹 기반 어텐션 및 액션 인지 마스킹 기법을 제안한 WACV 2023 Oral 논문 요약입니다.
Tag Video-Understanding
Calibrated Attention Masking Network for Temporal Action Localization 시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크 비디오 영상에서 특정 행동이 일어난 시작점과 끝점(시간적 경계)을 정밀하게 검출하기 위한 보정형 어텐션 마스킹(Calibrated Attention Masking) 기술에 대해 다룹니다.
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL [WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출 비디오 내 행동 구간 검출의 정확도를 높이기 위해 특정 행동 정보에 초점을 맞추는 그룹 기반 어텐션 및 액션 인지 마스킹 기법을 제안한 WACV 2023 Oral 논문 요약입니다.
Tag Hand-Pose
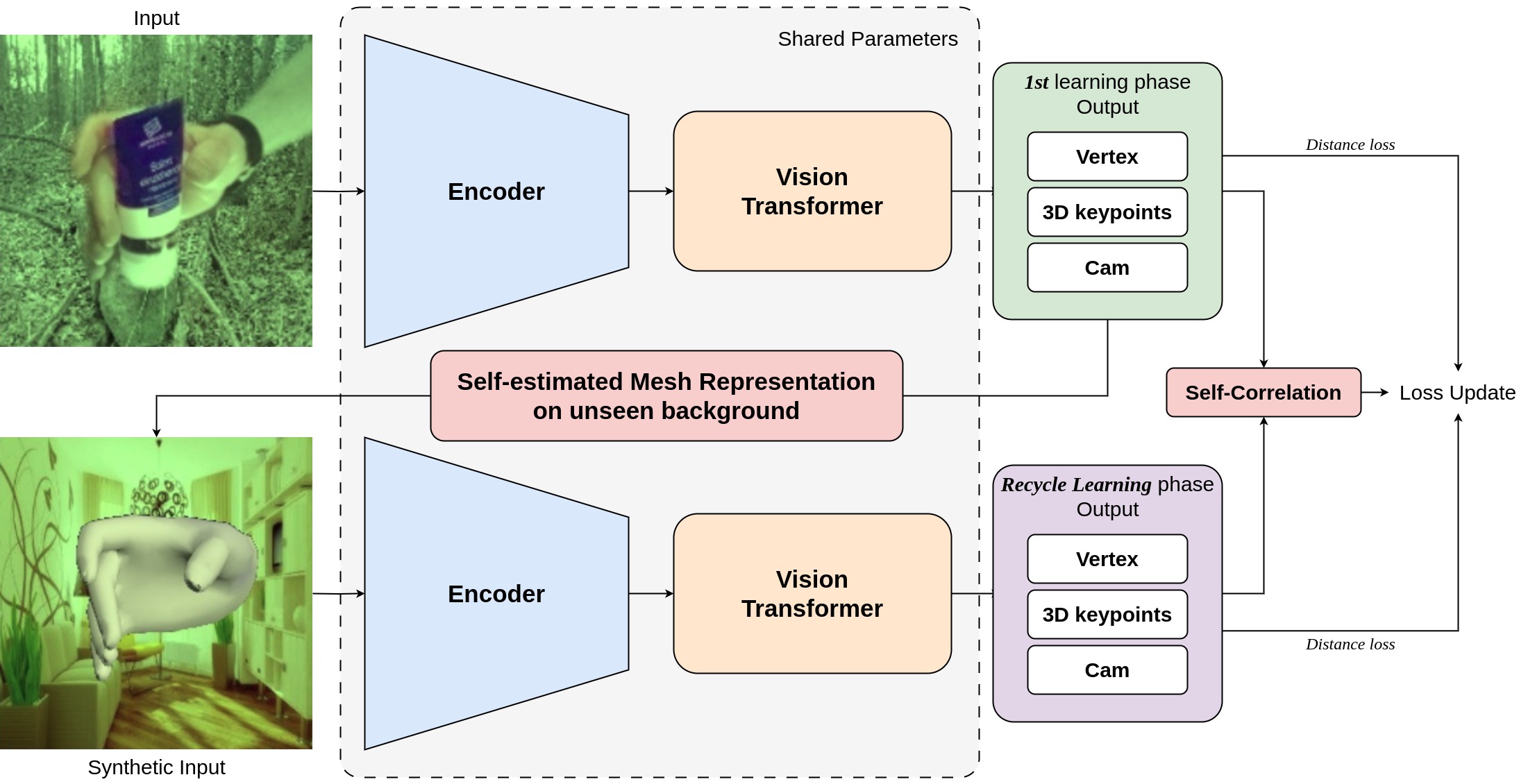
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation 3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법
3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법 3차원 손 메쉬 및 관절 추정의 정확도를 극대화하기 위해, 합성 데이터(Synthetic data)와 실데이터 간의 도메인 갭을 극복하는 메쉬 재활용 학습(Recycle Learning) 기법에 대해 분석합니다.
Tag Mesh-Recovery
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation 3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법
3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법 3차원 손 메쉬 및 관절 추정의 정확도를 극대화하기 위해, 합성 데이터(Synthetic data)와 실데이터 간의 도메인 갭을 극복하는 메쉬 재활용 학습(Recycle Learning) 기법에 대해 분석합니다.
Tag Self-Supervised-Learning
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer 프레임 일부만 레이블링된 비디오 환경에서 트랜스포머의 시간-공간 토큰 학습 및 셀프 지도 마스킹 기법을 통해 관절 가림 현상(Occlusion)을 복원하는 OTPose 프레임워크를 분석합니다.
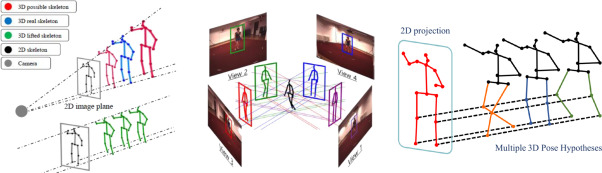
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크
MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크 3D 라벨이 없는 일반 비디오 환경에서 투영 모호성(Depth Ambiguity)을 해결하고 일관된 3D 카메라 공간으로 관절을 들어 올리는(Lifting) MHCanonNet 프레임워크를 분석합니다.
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation 3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법
3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법 3차원 손 메쉬 및 관절 추정의 정확도를 극대화하기 위해, 합성 데이터(Synthetic data)와 실데이터 간의 도메인 갭을 극복하는 메쉬 재활용 학습(Recycle Learning) 기법에 대해 분석합니다.
Tag arXiv-2023
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation 3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법
3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법 3차원 손 메쉬 및 관절 추정의 정확도를 극대화하기 위해, 합성 데이터(Synthetic data)와 실데이터 간의 도메인 갭을 극복하는 메쉬 재활용 학습(Recycle Learning) 기법에 대해 분석합니다.
Tag 3D-Pose-Estimation
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크
MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크 3D 라벨이 없는 일반 비디오 환경에서 투영 모호성(Depth Ambiguity)을 해결하고 일관된 3D 카메라 공간으로 관절을 들어 올리는(Lifting) MHCanonNet 프레임워크를 분석합니다.
Tag Pattern-Recognition-2024
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크
MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크 3D 라벨이 없는 일반 비디오 환경에서 투영 모호성(Depth Ambiguity)을 해결하고 일관된 3D 카메라 공간으로 관절을 들어 올리는(Lifting) MHCanonNet 프레임워크를 분석합니다.
Tag Action-Recognition
Infant Behavior Video Analysis using Pose Estimation and Action Recognition Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안
Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안 영유아의 대근육 운동 발달 수준을 평가하고 예측하기 위해 DCPose 및 I3D 모델을 활용한 비디오 행동 분석 솔루션을 제안합니다.
Tag Infant-Development
Infant Behavior Video Analysis using Pose Estimation and Action Recognition Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안
Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안 영유아의 대근육 운동 발달 수준을 평가하고 예측하기 위해 DCPose 및 I3D 모델을 활용한 비디오 행동 분석 솔루션을 제안합니다.
Tag Transformer
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer 프레임 일부만 레이블링된 비디오 환경에서 트랜스포머의 시간-공간 토큰 학습 및 셀프 지도 마스킹 기법을 통해 관절 가림 현상(Occlusion)을 복원하는 OTPose 프레임워크를 분석합니다.
Tag SMC-2022
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer 프레임 일부만 레이블링된 비디오 환경에서 트랜스포머의 시간-공간 토큰 학습 및 셀프 지도 마스킹 기법을 통해 관절 가림 현상(Occlusion)을 복원하는 OTPose 프레임워크를 분석합니다.