Kyung-Min Jin
Machine Learning Engineer | Building multimodal intelligence & Embodied AI
Kinematic-aware Hierarchical Attention Network
Solving temporal jitter and joint occlusions in video-based human pose estimation by integrating physical laws of motion (velocity & acceleration) into hierarchical spatio-temporal transformer architectures.
Read Paper & Code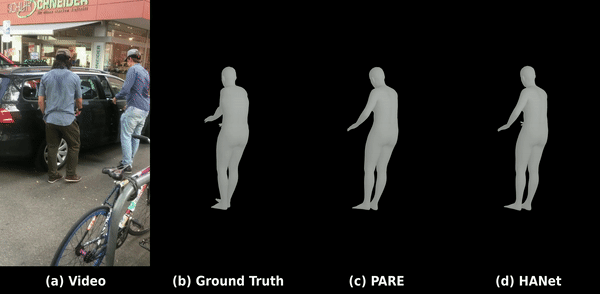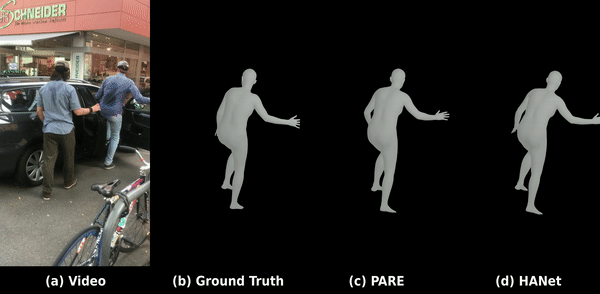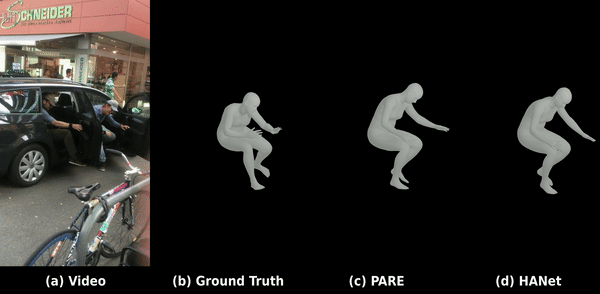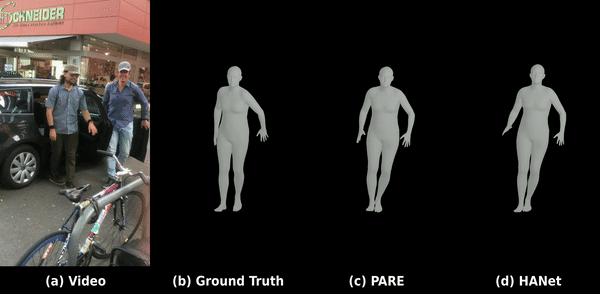
운동학을 고려한 계층적 어텐션 네트워크 (HANet)
비디오 기반 3D 인체 포즈 추정 시 발생하는 프레임 간 지터링과 조인트 가려짐 문제를 해결하기 위해 물리적 운동 법칙(속도 및 가속도)을 계층적 시공간 트랜스포머 아키텍처에 통합하여 해결합니다.
논문 및 코드 보기
Research Interests
Multimodal Intelligence
Aligning vision-language-audio modalities, cross-modal continual learning, and RL policy alignment (GRPO/DPO).
Computer Vision / Pose
2D/3D human and hand pose estimation, spatial-temporal attention transformers, and quantized-aware training.
Embodied AI / Robotics
Robotic perception, QA dataset construction, and developing QA systems integrating RAG with ROS2.
관심 연구 분야
멀티모달 인공지능
시각-언어-오디오 모달리티 정렬, 교차 모달리티 지속 학습(Continual Learning) 및 RL 기반 정렬 기법(GRPO/DPO) 연구.
컴퓨터 비전 / 포즈
2D/3D 인체 및 손 포즈 추정, 시공간 어텐션 트랜스포머 모델 및 배포를 위한 양자화 인식 학습(QAT) 연구.
Embodied AI / 로봇공학
로봇 인지 기술, 로봇 관련 QA 데이터셋 구축 및 RAG와 ROS2를 결합한 QA 시스템 개발 연구.
Latest News
"MAPLE: Modality-Aware Post-training and Learning Ecosystem" arXiv Preprinted
Co-authored research proposing modality-aware post-training pipelines.Transitioned to Advanced Robotics Lab, LG Electronics
Focusing on QA dataset construction and RAG-ROS2 QA system development (선임연구원).Serving as Active Reviewer for NeurIPS, BMVC & ECCV
Reviewer activities for major machine learning and computer vision venues.최근 소식
"MAPLE: 모달리티 인식 포스트 트레이닝 및 학습 에코시스템" arXiv 프리프린트 등록
모달리티 인식 포스트 트레이닝 파이프라인을 제안하는 공동 연구 논문입니다.LG전자 로봇선행연구소(Advanced Robotics Lab) 이동
QA 데이터셋 구축 및 RAG-ROS2 결합 QA 시스템 개발 담당 (선임연구원).NeurIPS, BMVC 및 ECCV 학회 심사위원(Reviewer) 활동
기계학습 및 컴퓨터 비전 최우수 국제학회 논문 심사위원 활동 진행 중.Work & Education Timeline
LG Electronics
Full-time · 3 yrs 4 mos (Mar 2023 - Present)
Advanced Robotics Lab
Robot Cognition Task Specialist (선임연구원)
Jan 2026 - Present
Focusing on robotic perception, QA dataset construction, and developing QA systems integrating RAG with ROS2. Developing robotic query response capabilities.
AI Lab
Multimodal Task Specialist (연구원)
Jul 2023 - Dec 2025
Researched "Semantic-Aware Mutual Information Factorized Learning (SAMIF)" for multimodal segmentation. Deployed action detection/control models to Qualcomm Neural SDK via ONNX. Designed audio tower and LLM cross modal continual learning pipeline. Researched GRPO/DPO online policy optimization for MLLMs with Toronto AI Lab.
Cognitive Vision TP
Cognitive Vision TP Researcher (연구원)
Mar 2023 - Jul 2023
Optimized body pose estimation models using quantized-aware training for LG TV edge device deployment. Designed RecycleNet for hand mesh synthesis and proposed grouping attention mechanism per finger, achieving state-of-the-art performance in PA-MPJPE.

Korea University
7 yrs (Mar 2016 - Feb 2023)
Graduate School
M.S. in Artificial Intelligence (PRML Lab)
Sep 2021 - Feb 2023
Advised by Prof. Seong-Hwan Lee. Specialized in video-based human pose estimation, spatial-temporal attention transformers, and mutual learning. Published first-author papers at WACV 2023 (Oral) and Neural Networks. Graduated with a perfect GPA of 4.50/4.50.
College of Informatics
B.S. in Computer Science & CSE / Artificial Intelligence
Mar 2016 - Aug 2021
Completed double majors in Computer Science and Artificial Intelligence. Graduated with Honors. Cumulative GPA of 3.99/4.50 (AI major GPA: 4.17/4.50).
Voice Caddie
AI Assistant Device Developer · 7 mos (May 2020 - Nov 2020)
Developed and deployed golf swing pose estimation models, action localization modules, and specialized video annotation tools. Utilized Python, PyTorch, C++, and OpenCV.
Da Vinci Co., Ltd.
Frontend Developer · 8 mos (Jul 2020 - Feb 2021)
Deployed and maintained interactive map-based applications, link saving helper utilities, and browser extensions. Leveraged modern React, TypeScript, Next.js, and React Native codebases.
Klue
Frontend Developer · 3 yrs 9 mos (Jul 2019 - Mar 2023)
Designed, deployed, and maintained a course evaluation service utilized by university students. Managed state architectures using Redux and MobX, and implemented clean, responsive components in React and TypeScript.
경력 및 학력 사항
LG전자
정직원 · 3년 4개월 (2023.03 - 현재)
로봇선행연구소 (Advanced Robotics Lab)
로봇 인지 태스크 선임연구원
2026.01 - 현재
로봇 인지 기술, 로봇 관련 QA 데이터셋 구축 및 RAG와 ROS2를 결합한 QA 시스템 개발 업무를 담당하고 있습니다.
AI연구소 (AI Lab)
멀티모달 태스크 선임 연구원(연구원)
2023.07 - 2025.12
멀티모달 세그멘테이션을 위한 "SAMIF" 모델 연구를 진행했습니다. 행동 검출 및 제어 모델을 ONNX를 통해 Qualcomm Neural SDK에 이식했습니다. 오디오 인코더 및 LLM의 교차 모달 지속 학습 파이프라인을 설계했습니다. 토론토 AI 연구소와 협력하여 MLLM을 위한 GRPO/DPO 온라인 정책 최적화 연구를 수행했습니다.
영상인지 TP (Cognitive Vision TP)
영상인지 연구원 (연구원)
2023.03 - 2023.07
LG TV 엣지 디바이스 배포용 인체 포즈 추정 모델을 양자화 인식 학습(QAT)을 사용하여 최적화했습니다. 핸드 메쉬 합성을 위한 RecycleNet을 설계하고 손가락별 그룹핑 어텐션 메커니즘을 제안하여 PA-MPJPE SOTA 성능을 달성했습니다.
고려대학교
7년 (2016.03 - 2023.02)
대학원 (Graduate School)
인공지능학과 석사 학위 수여 (PRML 연구실)
2021.09 - 2023.02
이성환 교수님의 지도하에 연구를 수행했습니다. 비디오 기반 인체 포즈 추정, 시공간 어텐션 트랜스포머 및 상호 학습 연구를 전문으로 하였습니다. WACV 2023 (Oral) 및 Neural Networks 저널에 제1저자 논문을 게재했습니다. 만점 평점(4.50/4.50)으로 졸업했습니다.
정보대학 (College of Informatics)
컴퓨터학과 학사 졸업 / 인공지능학 복수전공
2016.03 - 2021.08
컴퓨터학과와 인공지능학 복수전공을 이수했습니다. 우등 졸업(Graduated with Honors)을 하였으며, 전체 평점 3.99/4.50 (인공지능 전공 평점: 4.17/4.50)을 취득했습니다.
보이스캐디 (Voice Caddie)
AI 어시스턴트 디바이스 개발자 · 7개월 (2020.05 - 2020.11)
골프 스윙 포즈 추정 모델, 행동 국소화(action localization) 모듈 및 전용 비디오 어노테이션 툴을 개발하고 탑재했습니다. Python, PyTorch, C++ 및 OpenCV를 활용하였습니다.
다빈치 (Da Vinci Co., Ltd.)
프론트엔드 개발자 · 8개월 (2020.07 - 2021.02)
인터랙티브 지도 기반 애플리케이션, 링크 저장 도우미 유틸리티 및 브라우저 확장 프로그램을 배포하고 관리했습니다. React, TypeScript, Next.js 및 React Native 기반의 최신 코드베이스를 활용했습니다.
클루 (Klue)
프론트엔드 개발자 · 3년 9개월 (2019.07 - 2023.03)
대학생들이 사용하는 강의 평가 서비스(KLUE)를 설계, 배포 및 유지관리했습니다. Redux와 MobX를 사용해 전역 상태 구조를 관리하고, React와 TypeScript를 사용하여 직관적이고 반응형 컴포넌트들을 개발했습니다.
Tech Stack & Skills
Deep Learning & AI
Robotics & LLM / RAG
Programming Languages
Development Tools & Frontend
기술 스택 및 기술 역량
딥러닝 & 인공지능 (Deep Learning & AI)
로봇 인지 및 LLM / RAG
프로그래밍 언어 (Languages)
개발 도구 및 프론트엔드 (Tools & Frontend)
Awards & Honors
Grand Prize (대상)
Miso AI Model Development Challenge
Dec 2021 · Ministry of Science and ICTR&D Scholarships
LG Electronics Scholarship Award
Sep 2022 · LG ElectronicsOral Presentations (WACV, SMC)
Invited Oral Presentations at Top Venues
2022 - 2023 · WACV 2023, SMC 2022Encouragement Prize
Smart Campus Dataton
Jul 2020 · Korea University수상 및 선정 내역
대상 (Grand Prize)
Miso AI 모델 개발 챌린지
2021.12 · 과학기술정보통신부LGenius 산학장학생 선정
LG전자 R&D 산학 장학생 선발
2022.09 · LG전자우수 학회 구두 발표 선정 (WACV, SMC)
최우수 학회(WACV 2023 Oral) 구두 발표 초청
2022 - 2023 · WACV 2023, SMC 2022장려상 수상
스마트 캠퍼스 데이터톤
2020.07 · 고려대학교Open-Source & Tutorials
- HANet (WACV 2023): PyTorch implementation of Kinematic-aware Hierarchical Attention Network [Repository]
- OTPose (SMC 2022): Occlusion-Aware Transformer for video pose estimation [Repository]
- Online Course Instructor: 2D Pose Estimation Tutorial Course (Inflearn, Mar. 2023)
오픈소스 및 강의 활동
All Stories
블로그 포스트
OTPose: Occlusion-Aware Transformer for Pose Estimation in Sparsely-Labeled Videos OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer
OTPose: 드문 레이블 비디오에서 가림 현상을 해결하는 Occlusion-Aware Transformer 프레임 일부만 레이블링된 비디오 환경에서 트랜스포머의 시간-공간 토큰 학습 및 셀프 지도 마스킹 기법을 통해 관절 가림 현상(Occlusion)을 복원하는 OTPose 프레임워크를 분석합니다.
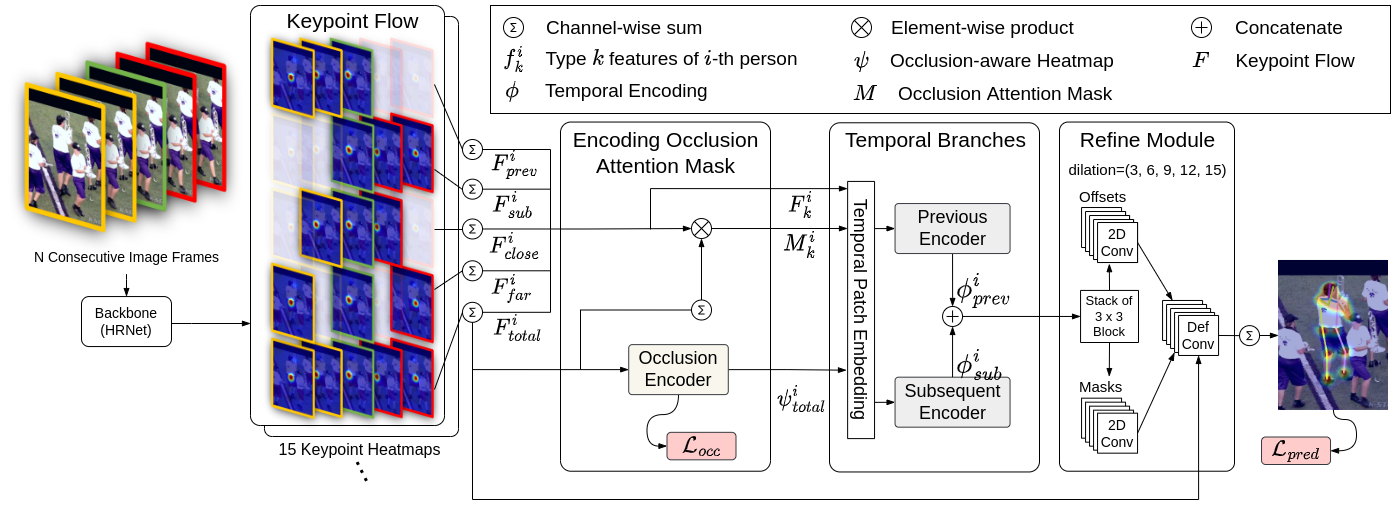
Infant Behavior Video Analysis using Pose Estimation and Action Recognition Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안
Pose Estimation 및 Action Recognition 기반 영유아 행동 분석 모델 및 활용 제안 영유아의 대근육 운동 발달 수준을 평가하고 예측하기 위해 DCPose 및 I3D 모델을 활용한 비디오 행동 분석 솔루션을 제안합니다.

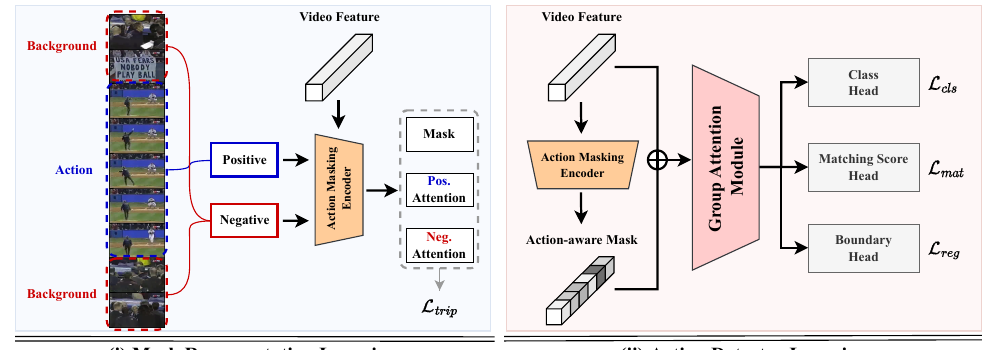
Calibrated Attention Masking Network for Temporal Action Localization 시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크
시간적 행동 구간 검출을 위한 캘리브레이션 어텐션 마스킹 네트워크 비디오 영상에서 특정 행동이 일어난 시작점과 끝점(시간적 경계)을 정밀하게 검출하기 위한 보정형 어텐션 마스킹(Calibrated Attention Masking) 기술에 대해 다룹니다.
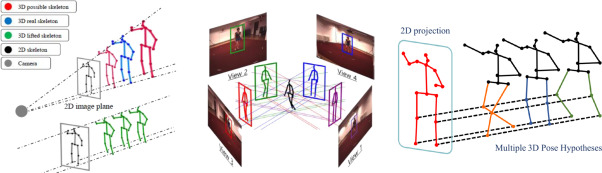
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크
MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크 3D 라벨이 없는 일반 비디오 환경에서 투영 모호성(Depth Ambiguity)을 해결하고 일관된 3D 카메라 공간으로 관절을 들어 올리는(Lifting) MHCanonNet 프레임워크를 분석합니다.
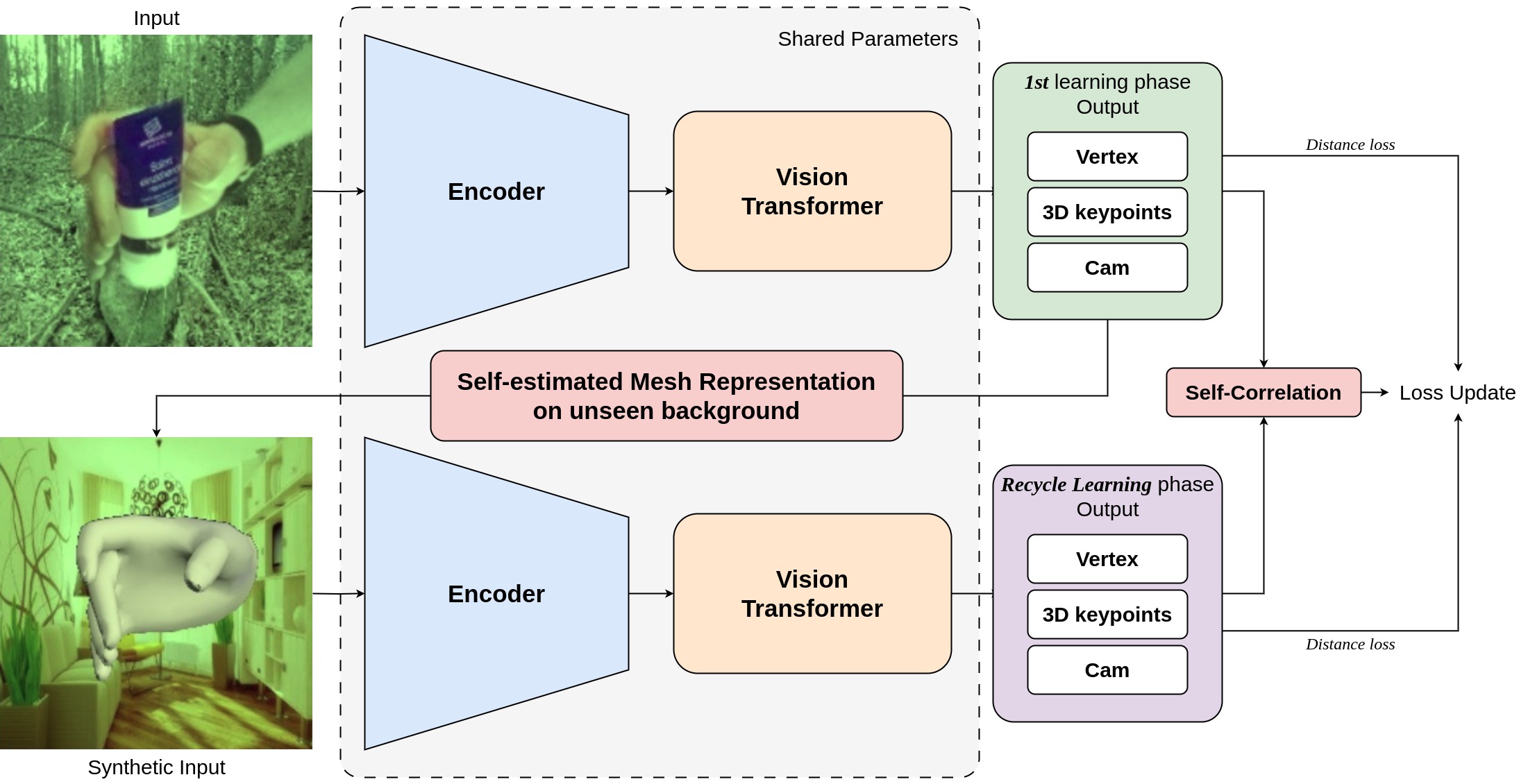
Mesh Represented Recycle Learning for 3D Hand Pose and Mesh Estimation 3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법
3D 손 포즈 및 메쉬 복원을 위한 메쉬 표상 재활용 학습법 3차원 손 메쉬 및 관절 추정의 정확도를 극대화하기 위해, 합성 데이터(Synthetic data)와 실데이터 간의 도메인 갭을 극복하는 메쉬 재활용 학습(Recycle Learning) 기법에 대해 분석합니다.
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL [WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출 비디오 내 행동 구간 검출의 정확도를 높이기 위해 특정 행동 정보에 초점을 맞추는 그룹 기반 어텐션 및 액션 인지 마스킹 기법을 제안한 WACV 2023 Oral 논문 요약입니다.
Google Scholar Metrics
| Metric | All |
|---|---|
| Citations | 97 |
| h-index | 5 |
| i10-index | 4 |
GitHub Activity
Kyung-Min Jin's Github Contributions