
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation
MHCanonNet: 자기지도 기반 3D 인체 포즈 추정을 위한 다중 가설 캐노니컬 리프팅 네트워크
2D 이미지/비디오 좌표에서 3D 공간상의 인체 좌표를 추정해 내는 3D Human Pose Lifting 기술은 컴퓨터 비전 분야의 난제 중 하나입니다. 단일 시점의 2D 입력 데이터만을 이용해 3D 공간을 복원할 때 발생하는 깊이의 모호성(Depth Ambiguity)(하나의 2D 평면 실루엣에 여러 개의 3D 관절 배치가 대응될 수 있는 현상) 때문입니다.
더불어 야외(In-the-wild) 비디오 환경에서는 3D 그라운드 트루스(GT) 획득이 불가능하여 기존 지도학습 모델들은 무력해집니다.
본 포스트에서는 국제 학술지 Pattern Recognition (2024)에 게재된 공동 연구 논문인 MHCanonNet의 자기지도 3D 리프팅 아키텍처를 소개합니다.
1. 3D Lifting의 핵심 한계: 투영 모호성
하나의 2D 평면 이미지 좌표가 주어졌을 때, 3차원 깊이 정보($Z$-depth)는 수학적으로 유일한 해를 가질 수 없습니다.
- 자기지도학습(Self-Supervised Learning) 환경에서는 3D GT가 없기 때문에 모델이 3D 좌표를 예측한 뒤 다시 2D로 투영(Re-projection)해보고 원본 2D와 일치하는지를 검증하는 Projection Loss를 주로 사용합니다.
- 하지만, 깊이 왜곡이 심하게 발생한 엉터리 3D 포즈도 카메라 투영을 거치면 원래 2D 포즈와 완벽히 겹쳐 보이는 기하학적 버그가 생깁니다.
2. MHCanonNet 핵심 아키텍처
MHCanonNet은 이 문제를 캐노니컬 좌표계(Canonical Space)와 다중 가설(Multi-Hypothesis) 모델링을 통해 원천적으로 해결합니다.
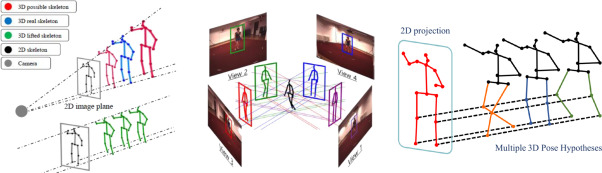
① Canonical Space Alignment (캐노니컬 공간 정렬)
- 카메라의 시점(Viewpoint) 변화에 모델이 혼란을 겪는 것을 막기 위해, 추정된 3D 관절들을 카메라 각도에 무관한 인체 고유의 로컬 가상 좌표계(Canonical Coordinate System)로 정렬하여 크기 및 회전 성분을 분리 학습시킵니다.
② Multi-Hypothesis Generation (다중 가설 생성)
- 깊이의 모호성을 해결하기 위해 단 하나의 3D 포즈만 생성하는 대신, 기하학적으로 타당한 여러 개의 3D 가설(Hypotheses)을 동시에 릴리즈합니다.
- 다수의 가설 중 신체 물리적 뼈대 길이 보존성(Bone-length preservation constraint)과 프레임 간 3D 궤적 일치도가 가장 높은 최적의 3D 포즈를 가려내는 선택적 피드백 루프를 적용했습니다.
3. 결론 및 의의
MHCanonNet은 3D 모션 캡처 장비가 없는 일반 웹 비디오, 영화, 야외 스포츠 동영상에서도 고정밀 3차원 바디 구조 복원이 가능함을 증명했습니다. 자기지도 학습 기반 리프팅 분야에서 깊이 모호성을 기하학적으로 방어하는 강력한 베이스라인을 제안하며 패턴 인식 분야의 주요 연구 성과로 자리 잡았습니다.
MHCanonNet: Multi-Hypothesis Canonical Lifting Network for Self-Supervised 3D Pose Estimation
Estimating 3D human coordinates from 2D image or video coordinates (3D Human Pose Lifting) is a fundamental computer vision challenge due to depth ambiguity, where a single 2D projection can correspond to multiple valid 3D joint configurations.
Furthermore, acquiring 3D ground-truth (GT) labels for in-the-wild videos is extremely difficult, limiting the applicability of supervised methods.
This post highlights MHCanonNet, published in Pattern Recognition (2024), which tackles these limitations via a self-supervised 3D lifting framework.
1. The Core Limitation: Projection Ambiguity
Mathematically, a 2D pose cannot resolve a unique 3D reconstruction without depth cues.
- Self-supervised systems bypass this by projecting estimated 3D joints back to 2D space and calculating a projection loss against the input 2D coordinates.
- However, a physically distorted 3D pose can still project perfectly onto the 2D silhouette, causing the optimizer to get stuck in geometrically invalid local minima.
2. Core Concepts of MHCanonNet
MHCanonNet addresses projection ambiguity using a Canonical Coordinate Space and Multi-Hypothesis Modeling.
① Canonical Space Alignment
- To prevent viewpoint changes from confusing the network, estimated 3D joints are transformed into a view-independent canonical frame, decoupling scale and rotation.
② Multi-Hypothesis Generation
- Instead of outputting a single 3D pose, the network generates multiple geometrically plausible 3D hypotheses.
- It then uses bone-length preservation and temporal trajectory constraints to identify and select the most physically correct 3D pose among the candidates.
3. Impact & Conclusion
MHCanonNet enables high-precision 3D human pose reconstruction from standard outdoor videos without expensive motion-capture systems. By geometrically solving depth ambiguity under self-supervision, it establishes a robust baseline for in-the-wild 3D lifting.