
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation
비디오 포즈 추정을 위한 물리 법칙 기반 계층적 어텐션 네트워크 (HANet & M-HANet)
비디오 기반 3차원 인체 포즈 추정(Human Pose Estimation)에서 단일 이미지 모델(Frame-by-frame detector)을 그대로 사용하면 가장 흔하게 마주하는 문제는 프레임 간 예측값의 미세한 흔들림(Jittering/Trembling)입니다.
인간은 물리적으로 순간 이동을 하거나 관절이 비이상적인 속도로 꺾이지 않습니다. 즉, 인체의 관절 움직임은 일정한 물리적 속도와 가속도의 연속성(Kinematic Continuity)을 가집니다.
본 포스트에서는 이러한 물리적 제약 조건을 트랜스포머의 어텐션 메커니즘에 직접 주입하여 학습 시 흔들림을 원천 억제하는 HANet (WACV 2023 Oral)과, 이를 자가지도 마스킹 기법으로 고도화하여 국제 학술지 Neural Networks (2024)에 게재된 M-HANet (Masked-HANet)의 설계 개념을 분석합니다.
1. 모델 아키텍처 (HANet)
다음은 Kinematic-aware 계층적 어텐션 네트워크의 전체 아키텍처입니다. 입력 프레임들로부터 공간적 키포인트 feature을 추출한 뒤, 인체 골격 구조를 따라 시간적 문맥을 전파합니다.
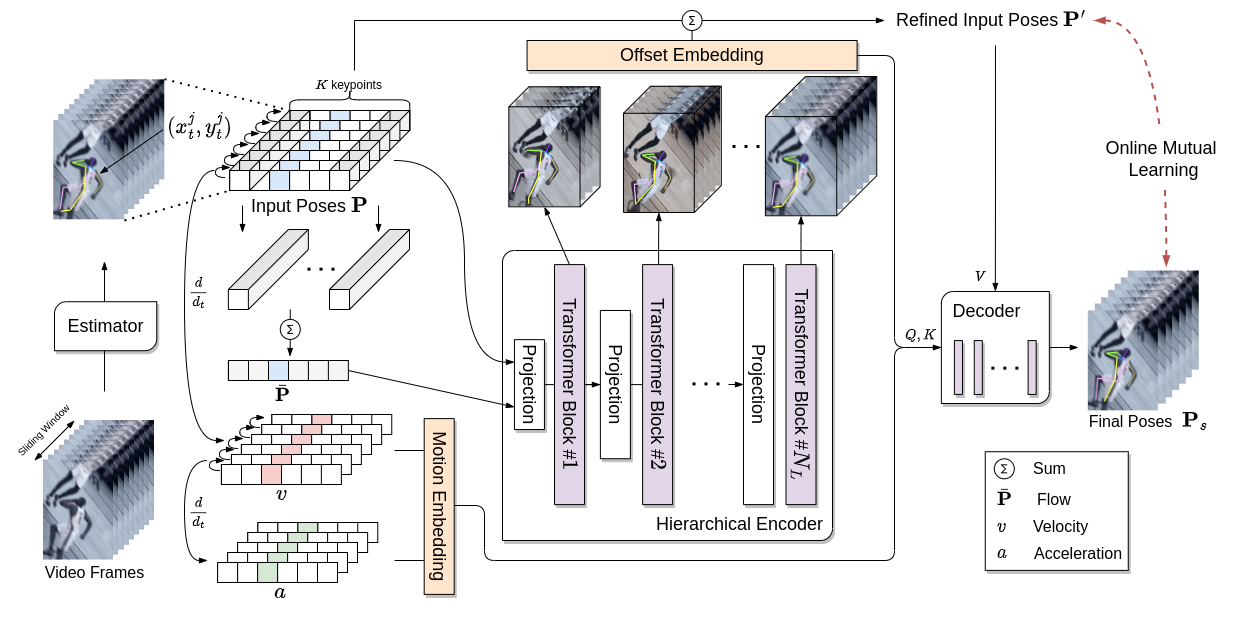
그림 1: 계층적 어텐션 블록과 시공간 인코더를 포함하는 HANet의 전체 파이프라인.
네트워크는 다음과 같은 두 가지 핵심 요소로 구성됩니다:
- 계층적 어텐션 인코더 (Hierarchical Attention Encoder): 서로 다른 해상도 레이어로부터 멀티스케일 시공간 어텐션을 계산합니다.
- Kinematic-aware feature 파이프라인 (Kinematic-aware Feature Pipeline): 키포인트 예측을 유도하기 위해 속도(velocity)와 가속도(acceleration)를 명시적으로 모델링합니다.
2. Kinematic feature 기반 동적 시공간 어텐션
트랜스포머 모델의 표준 셀프 어텐션 매커니즘은 인체 골격 구조를 고려하지 않고 모든 키포인트를 동등하게 취급합니다. 반면, HANet은 Kinematic 관절 구조(kinematic joints)에 따라 어텐션을 계층적으로 세분화하여 연산합니다.
- 국소 어텐션 (Local Attention): 뼈대(bone)로 직접 연결된 인접 관절 사이(예: 손목과 팔꿈치, 팔꿈치와 어깨)에서 어텐션을 계산합니다.
- 전역 어텐션 (Global Attention): 양손의 협동 동작과 같이 거리가 먼 관절 간의 장기 의존성(long-range dependencies)을 포착합니다.
Kinematic feature 공식화 (Kinematic Feature Formulation)
물리적 운동 법칙을 신경망에 주입하기 위해, 시계열 좌표 정보를 바탕으로 키포인트의 동적 운동 feature을 계산합니다. $t$ 프레임에서 특정 관절의 $d$차원 좌표(2D 또는 3D)를 $p_t \in \mathbb{R}^d$라 정의할 때, 다음과 같이 속도와 가속도를 유도합니다:
-
속도 ($v_t$): \(v_t = p_t - p_{t-1}\)
-
가속도 ($a_t$): \(a_t = v_t - v_{t-1} = p_t - 2p_{t-1} + p_{t-2}\)
이러한 Kinematic feature들은 최초의 관절 임베딩과 결합(concatenation)되어, 급격한 움직임이나 심한 가려짐 상황에서도 물리적인 궤적을 외삽(extrapolate)함으로써 부드럽고 안정적인 추정을 가능하게 만듭니다.
3. M-HANet (Neural Networks 2024): 마스킹과 자가 지도 기법의 융합
저널 버전으로 확장된 M-HANet (Masked-HANet)은 “물리 법칙을 더 가혹한 환경에서도 잘 학습하게 할 방법이 없을까?”라는 고민에서 탄생했습니다.
① Masked Kinematic Continuity 학습
- 핵심 메커니즘: 입력 비디오 토큰 중 특정 프레임 구간의 속도/가속도 정보를 인위적으로 지우거나 노이즈를 섞어 입력합니다.
- 학습 목표: 모델은 가려지거나 왜곡된 물리 토큰 상태에서도, 이전 프레임들의 속도 진행 방향성과 가속도 벡터를 역산하여 빈 구간의 키포인트 궤적을 물리 법칙에 부합하도록 원복(Reconstruct)해내도록 자가지도 마스킹 손실함수(Masked Reconstruction Loss)를 통해 고도화 학습됩니다.
- 이 학습 기법은 현업 임베디드(Smart TV 등) 환경에서 일부 관절이 완전히 프레임 아웃되어 가려지더라도, 이전 관절 모션을 기반으로 물리 궤적을 완벽히 복원해내는 뛰어난 내구성을 보장합니다.
4. 시각적 데모 (실제 구동 예시)
다음은 JHMDB, AIST++, 3DPW 데이터셋에서 평가된 모델의 정성적 추정 결과로, 일관되고 매끄러운 3차원 인체 관절 및 SMPL 메쉬 복원 성능을 확인할 수 있습니다.
A. 2D 포즈 트래킹 (JHMDB 데이터셋)
빠른 스윙 동작과 강한 모션 블러가 있는 상황에서도 키포인트가 안정적으로 유지되는 것을 확인할 수 있습니다.

데모 1: 역동적인 움직임 상황에서의 2D 골격 추정 (Sub-JHMDB).
B. 3D 포즈 추정 및 SMPL 메쉬 복원 (AIST++ 데이터셋)
복잡한 댄스 동작 상황에서 3차원 관절 및 부드러운 SMPL 인체 메쉬 표면을 복원해 냅니다.
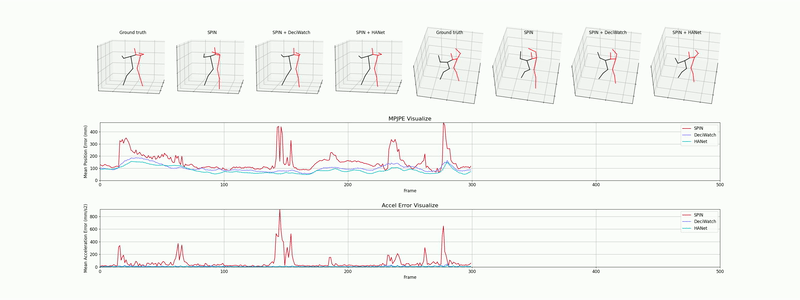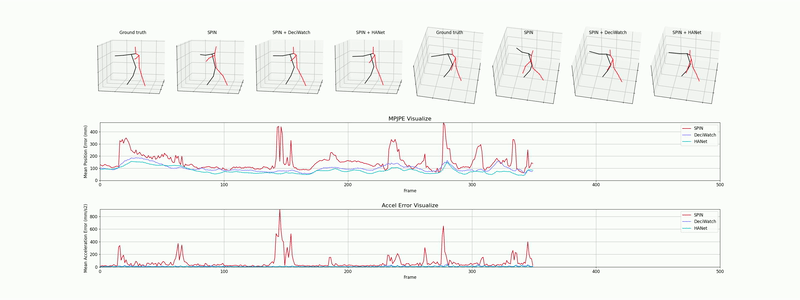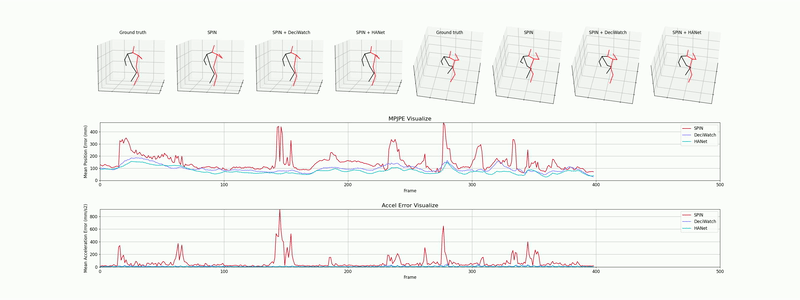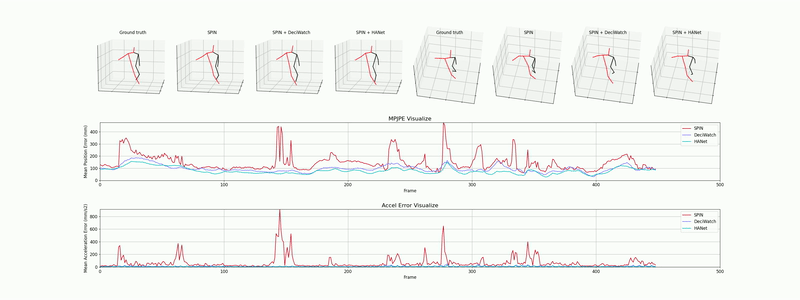
HANet: 3차원 관절 좌표 출력값.

HANet: 복원된 SMPL 인체 메쉬.
C. 야외 환경에서의 3D 바디 메쉬 복원 (3DPW 데이터셋)
도전적인 야외 환경 데이터셋인 3DPW 상의 평가 결과로, 가려짐과 빠른 동작 속에서도 강건한 포즈 복원 및 바디 형태 피팅을 보여줍니다.
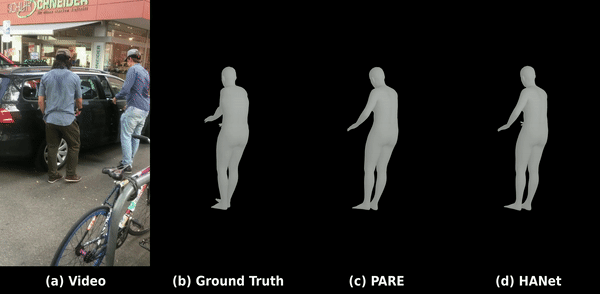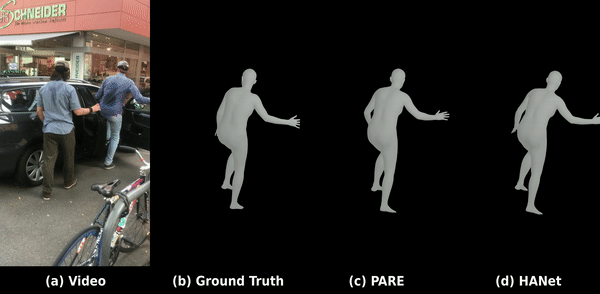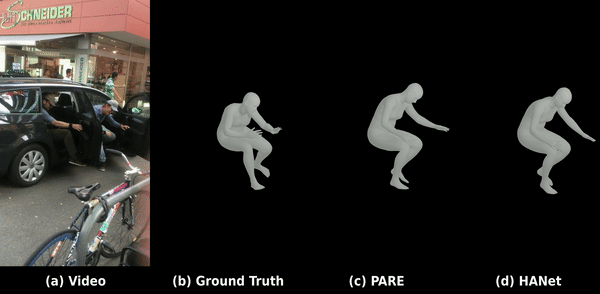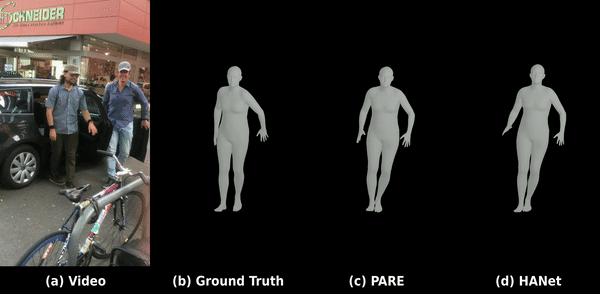
데모 2: 야외 가려짐 및 빠른 움직임 환경에서의 부드러운 3D 인체 메쉬 복원.
5. 온라인 상호 지도학습 (Online Cross-Supervision) 및 성능 지표
최초 입력 좌표 정보와 최종 정제된 출력값 간의 결합 최적화를 위해 온라인 상호 학습(online mutual learning) 목적 함수를 사용합니다. 학습 손실값에 따라 네트워크는 동적으로 지도 대상을 선택합니다:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{pose}} + \lambda_{\text{mutual}} \mathcal{L}_{\text{mutual}}(\pi_{\theta_{\text{in}}}, \pi_{\theta_{\text{out}}})\]정량적 성능 비교
제안하는 방법론은 주요 벤치마크 데이터셋에서 최고 성능(SOTA)을 달성했습니다:
| 데이터셋 | 평가 지표 | 입력 베이스라인 | HANet (본 연구) | 성능 향상폭 |
|---|---|---|---|---|
| Sub-JHMDB (2D) | PCK @ 0.05 | 57.3% | 91.9% | +34.6% |
| Human3.6M (3D) | MPJPE (mm) | 54.6mm | 52.8mm | -1.8mm |
| AIST++ (3D) | MPJPE (mm) | 107.7mm | 69.2mm | -38.5mm |
| 3DPW (SMPL) | MPJPE (mm) | 78.9mm | 77.1mm | -1.8mm |
주요 링크 및 자료
Kinematic Continuity-Aware Hierarchical Attention (HANet & M-HANet) for Video Pose Estimation
In video-based human pose estimation, maintaining temporal and kinematic consistency across frames is a major challenge. Standard frame-by-frame pose estimators often suffer from jittery predictions, joint swap errors, and failure under fast motion or occlusion because they do not model physical skeletal joints and anatomical limits.
This post summarizes our research on Kinematic-aware Hierarchical Attention Network (KHAN / HANet) (WACV 2023 Oral) and its journal extension Masked-HANet (M-HANet) (Neural Networks 2024) to resolve these issues by explicitly encoding joint relations and temporal continuity based on physical laws of motion.
1. Model Architecture (HANet)
Below is the overall architecture of the Kinematic-aware Hierarchical Attention Network. It extracts spatial keypoint features and propagates temporal context across skeletal structures.
Figure 1: Overall pipeline of HANet showcasing Hierarchical Attention blocks and Spatio-Temporal encoders.
The network incorporates two main components:
- A Hierarchical Attention Encoder that computes multi-scale spatio-temporal attention from different resolution layers.
- A Kinematic-aware Feature Pipeline that explicitly models velocity and acceleration to guide keypoint predictions.
2. Dynamic Spatial & Temporal Attention with Kinematic Features
Standard self-attention mechanisms in transformers treat all keypoints in a human body equally, ignoring the physical structure of the skeleton. In contrast, HANet structures attention hierarchically based on kinematic joints:
- Local Attention: Computes attention within adjacent joints (e.g., connecting wrist to elbow, elbow to shoulder) representing physical bone links.
- Global Attention: Captures long-range dependencies (e.g., left hand to right hand coordinating during an action).
Kinematic Feature Formulation
To enforce the physical laws of motion, we compute keypoint motion features based on sequential coordinates. Let $p_t \in \mathbb{R}^d$ be the $d$-dimensional coordinate (2D or 3D) of a body joint at frame $t$. We define the kinematic features as follows:
-
Velocity ($v_t$): \(v_t = p_t - p_{t-1}\)
-
Acceleration ($a_t$): \(a_t = v_t - v_{t-1} = p_t - 2p_{t-1} + p_{t-2}\)
These features are concatenated with the initial joint embeddings, enabling the network to learn smooth trajectories and handle heavy occlusion by extrapolating physical motion paths.
3. M-HANet (Neural Networks 2024): Integrating Self-Supervised Masking
M-HANet (Masked-HANet), the extended journal version, leverages self-supervised masking to further enhance physical constraint learning.
① Masked Kinematic Continuity Learning
- Mechanism: During training, we artificially mask or inject noise into the velocity and acceleration tokens of random frame intervals.
- Objective: The model is optimized using a Masked Reconstruction Loss, forcing it to reconstruct the missing keypoint coordinates by extrapolating the trajectory vectors of preceding frames.
- This strategy ensures excellent robustness in real-world deployment (e.g., Smart TVs), where the model can seamlessly predict joint positions even if a limb temporarily exits the frame.
4. Visual Demonstrations (Inference in Action)
Below are the qualitative tracking results evaluated on JHMDB, AIST++, and 3DPW datasets, demonstrating its ability to reconstruct poses and 3D SMPL meshes with smooth continuity.
A. 2D Pose Tracking (JHMDB Dataset)
Notice the stable keypoint tracking even during fast swinging motions and heavy motion blur.
Demo 1: 2D skeletal estimation under fast motion dynamics (Sub-JHMDB).
B. 3D Pose Estimation & SMPL Mesh Recovery (AIST++ Dataset)
Reconstruction of 3D skeletal joints and smooth SMPL body mesh surfaces under complex dance movements.
HANet: 3D joint coordinate outputs.
HANet: Reconstructed SMPL body mesh.
C. 3D Body Mesh Recovery (3DPW Dataset)
Evaluation on the challenging in-the-wild 3DPW dataset, demonstrating robust pose restoration and shape fitting.
Demo 2: Smooth 3D body mesh recovery under physical occlusions and fast motion in the wild.
5. Online Cross-Supervision & Results
To enable joint optimization between the initial input coordinates and the final refined outputs, we utilize an online mutual learning objective. Given training losses, the network dynamically selects targets:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{pose}} + \lambda_{\text{mutual}} \mathcal{L}_{\text{mutual}}(\pi_{\theta_{\text{in}}}, \pi_{\theta_{\text{out}}})\]Quantitative Performance Comparison
Our method achieved state-of-the-art results on major benchmarks:
| Dataset | Metric | Input Baseline | HANet (Ours) | Improvement |
|---|---|---|---|---|
| Sub-JHMDB (2D) | PCK @ 0.05 | 57.3% | 91.9% | +34.6% |
| Human3.6M (3D) | MPJPE (mm) | 54.6mm | 52.8mm | -1.8mm |
| AIST++ (3D) | MPJPE (mm) | 107.7mm | 69.2mm | -38.5mm |
| 3DPW (SMPL) | MPJPE (mm) | 78.9mm | 77.1mm | -1.8mm |
Resources