
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL
[WACV 2023 Oral] 그룹 어텐션 기반 액션 인지 마스킹 네트워크를 이용한 시간적 행동 구간 검출
비디오 내에서 특정 행동이 시작하고 끝나는 구간을 초 단위로 정밀하게 예측하는 시간적 행동 구간 검출(Temporal Action Localization, TAL) 과제는 비디오 스트리밍 편집, CCTV 실시간 관제 등 미디어 산업의 핵심 기술입니다.
기존의 모델들은 비디오 전체의 시간 흐름 정보를 동등하게 어텐션 연산함으로써, 정작 검출해야 할 핵심 행동 프레임과 배경(Background) 노이즈 프레임 간의 중요도 편차를 정밀하게 분리해내지 못하는 문제를 겪었습니다.
본 포스트에서는 WACV 2023 학회에 구두 발표(Oral)로 선정되었던 Action-Aware Masking Network with Group-Based Attention 논문의 핵심 디자인을 분석합니다.
1. 기존 TAL 모델의 한계점: 배경 노이즈와 어텐션 편중
전형적인 셀프 어텐션(Self-Attention) 레이어를 비디오 프레임 시퀀스에 적용하게 되면 다음과 같은 한계가 발생합니다:
- 배경 프레임의 간섭 (Background Interference): 비디오의 대부분을 차지하는 배경 프레임들이 행동 구간 프레임의 피처 학습을 교란시킵니다.
- 어텐션의 불균형: 행동이 일어나는 핵심 시퀀스보다 시각적으로 강한 특정 정적 프레임에 어텐션 가중치가 쏠리는 왜곡이 일어납니다.
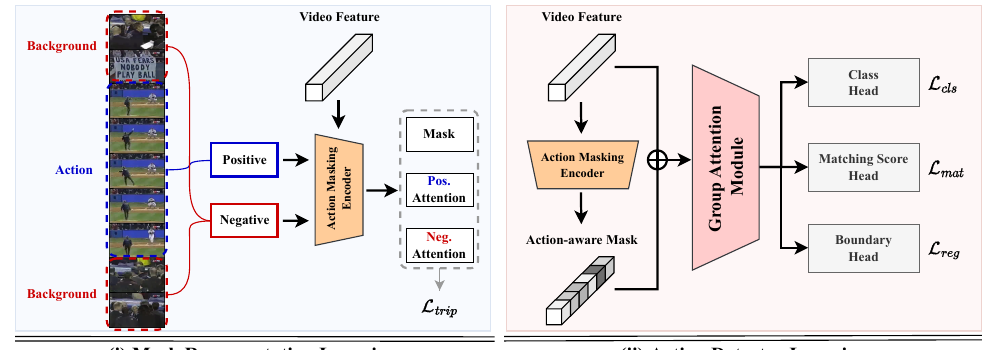
2. 제안 방법론: 액션 인지 마스킹 및 그룹 기반 어텐션
본 논문에서는 배경 노이즈를 제어하고 행동 구간의 임베딩 품질을 극대화하기 위해 두 가지 모듈을 제안했습니다.
① Group-Based Attention (그룹 기반 어텐션)
- 비디오 피처 채널을 여러 개의 그룹(Group) 단위로 쪼개고, 각 그룹이 비디오 내의 서로 다른 시간적 관계(Temporal dynamics)와 주파수 특징을 탐색하도록 가중치를 다변화합니다.
- 특정 프레임에 어텐션이 과도하게 집중되는 쏠림 현상을 방지하고 비디오의 복합적인 운동 맥락을 균형 있게 학습하게 만듭니다.
② Action-Aware Masking Network (액션 인지 마스킹)
- 프레임별 특징이 ‘행동’인지 ‘배경’인지 분류하는 중간 이진 분류기(Binary classifier)를 탑재합니다.
- 배경으로 판단되는 프레임들의 피처 값에 소프트 마스크(Soft Mask)를 씌워 어텐션 전파 과정에서 배경 노이즈가 행동 프레임으로 누출(Leakage)되는 것을 구조적으로 차단합니다.
3. 정량적 성과 및 의의
- 벤치마크 SOTA 성능 달성: 대표적인 행동 구간 검출 벤치마크 데이터셋인 ActivityNet 1.3 및 THUMOS14 상에서 기존 SOTA 검출기들을 압도하는 맵(mAP @ t-IoU) 점수 성능 향상을 달성했습니다.
- 본 논문은 배경 정보 차단을 위해 어텐션을 통계적으로 차단하는 액션 마스킹 기법을 제안하여 비디오 시간 영역 모델링의 강건성을 극대화했다는 점에서 큰 학술적 가치를 지닙니다.
[WACV 2023 Oral] Action-Aware Masking Network with Group-Based Attention for TAL
In video analytics, Temporal Action Localization (TAL) aims to locate both the boundaries and classes of actions in video streams, serving as a core technology for video editing and smart surveillance.
Existing TAL networks compute temporal self-attention uniformly across the video, struggle to isolate key action frames from noisy background frames.
This post reviews the architecture of Action-Aware Masking Network with Group-Based Attention, presented as an Oral Presentation at WACV 2023.
1. Limitations: Background Noise & Attention Collapse
Applying vanilla self-attention to video sequences introduces limitations:
- Background Interference: Redundant background frames contaminate the feature representations of active action frames.
- Attention Collapse: Attention weights often saturate on specific visually dominant frames rather than covering the entire action span.
2. Core Concepts: Group-Based Attention & Action Masking
To isolate background noise and refine action representation, the network introduces two main mechanisms:
① Group-Based Attention
- Splits video feature channels into multiple groups, letting each group capture distinct temporal dynamics.
- Prevents attention from saturating on a single frame, facilitating balanced learning of complex motions.
② Action-Aware Masking Network
- Incorporates an auxiliary binary classifier that determines if a frame is an ‘action’ or ‘background’.
- Applies a soft mask to background frames, preventing background feature leakage into action features during temporal propagation.
3. Quantitative Results & Impact
- State-of-the-Art Benchmarks: Achieved top-tier mean Average Precision (mAP) scores at various t-IoU thresholds on ActivityNet 1.3 and THUMOS14 datasets.
- The paper is highly regarded for introducing action masking to suppress background noise, significantly improving the stability of temporal video modeling.